An Introduction to the Goodreads APIs
Better GETting
GETting Something More Useful
So, okay, we've looked at code that's doing a little more, in trying to understand JSON and XML -- that is, what we're sending and getting back from the API. Let's look at an example of the code we were just seeing in action. Enter the title of a book (again, don't forget to use Chrome and the "enable cross-origin resources sharing" option turned on -- see below where we'll address this more fully):
Book data by string title
- Author:
- Book title:
- Goodreads average review:
See any issues with this? Let's look at this code again:
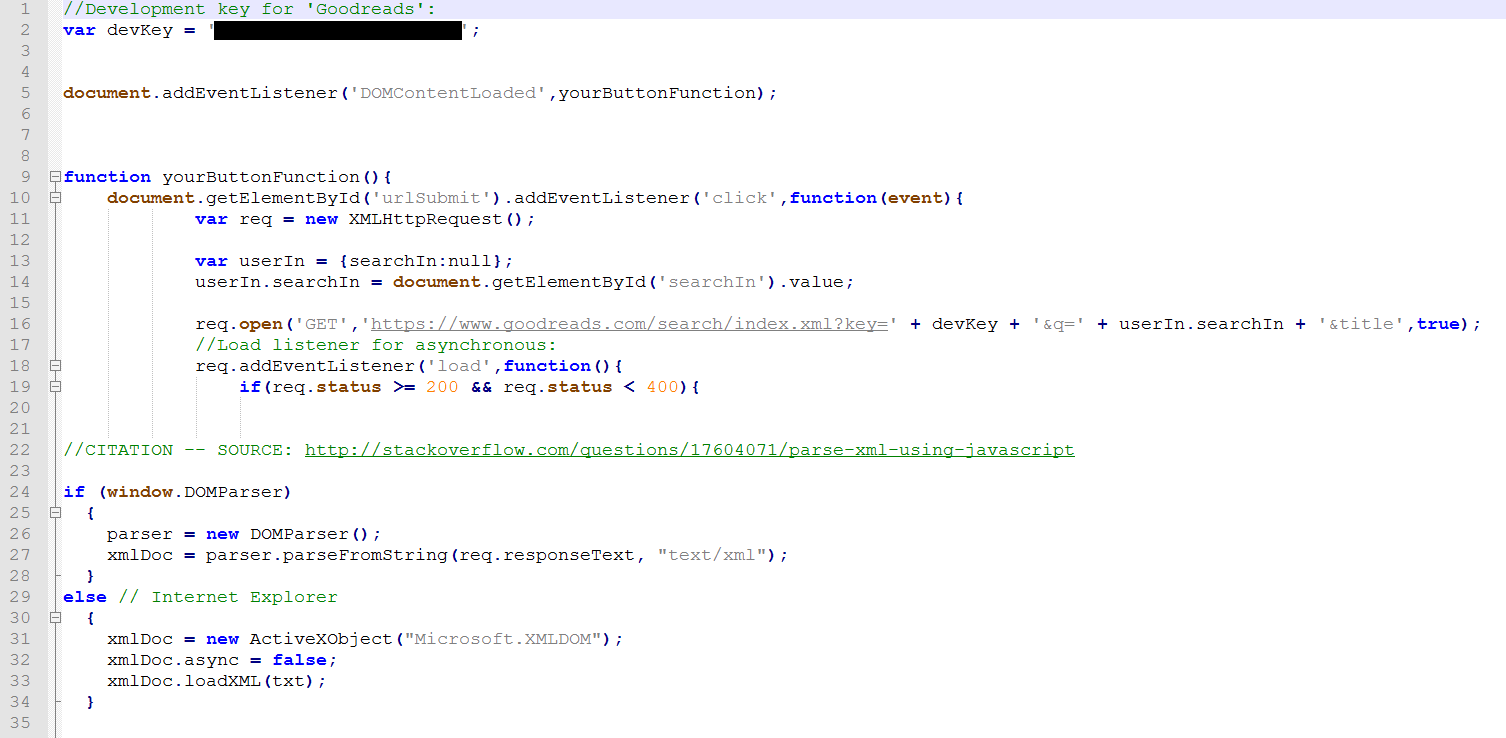
As we've already seen, this code takes the user input from an HTML text input with the label "searchIn" and appends it to our URL. It then receives back XML data, and parses that data. Now let's look at what we do with it:
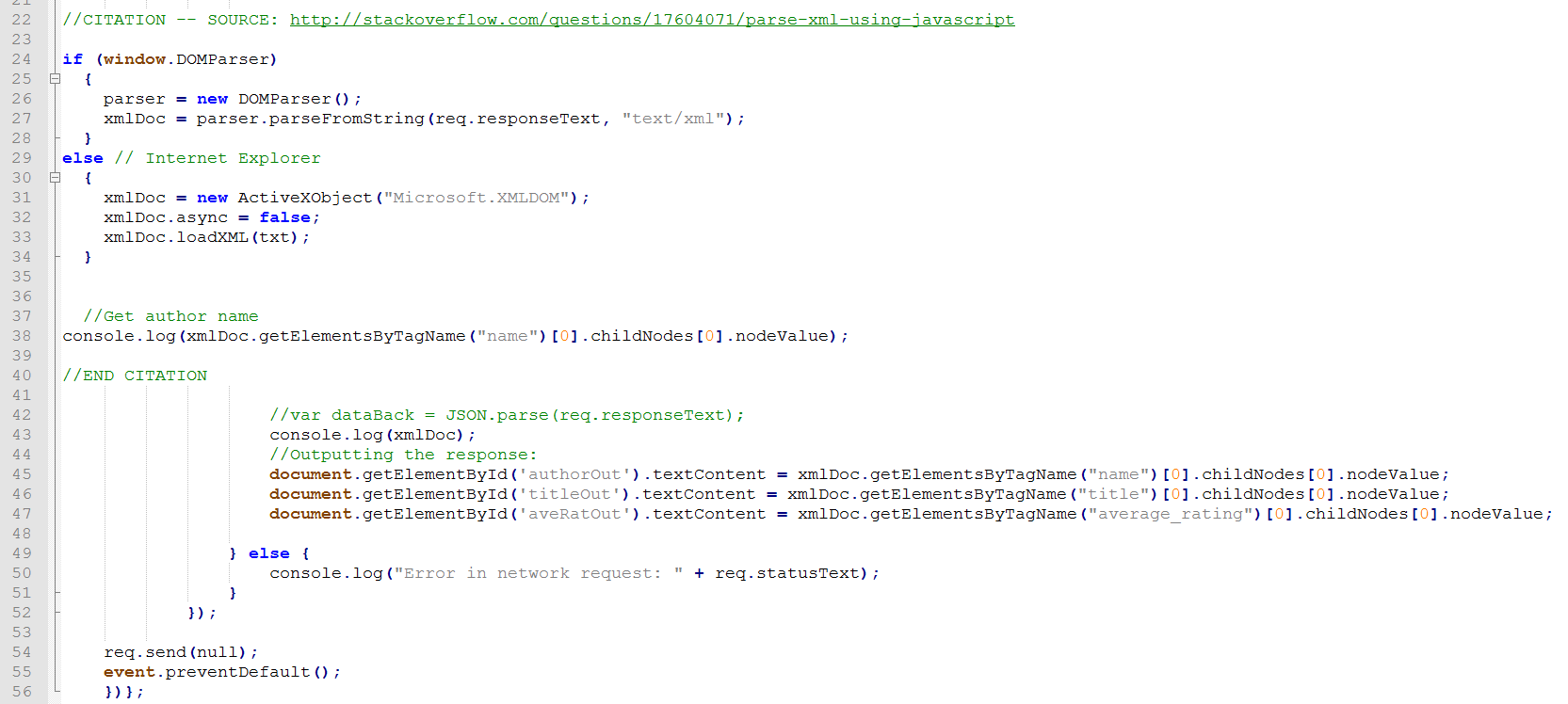
Here we take the parsed XML andß output the author value ("name" as it comes back from Goodreads). You'll need to check the specifics of the API to see how it is labeled. Again, the documentation on the source site isn't always the best, so logging to the console or checking in the document inspector gives you a better idea of exactly what you're being sent.
Again, you can look over the attribute-value pairs in this response from Goodreads to get a sense of how they are arranged:
{
"books": [{
"id": 265130,
"isbn": "0679600841",
"isbn13": "9780679600848",
"ratings_count": 173,
"reviews_count": 340,
"text_reviews_count": 23,
"work_ratings_count": 156294,
"work_reviews_count": 406706,
"work_text_reviews_count": 6703,
"average_rating": "4.10"
}]
}
In this case, we've parsed the XML and can display to HTML spans -- here there are three items of id "authorOut," "titleOut," and "aveRatOut." In the event of a status of 400 or more, we log the error.
Have you noticed an issue with this version? A title search will almost always send back more values than one, but in a parsing and display method like this, we will only get the first option. We also have no choice over what exactly is being searched. We'll add these elements in our next step!
Client-side vs Server-side
Before we move on to the final steps on our demo search engine, we need to address this nagging issue with CORS that's forcing us to use Chrome with an extension or very specific settings. As mentioned before, our CORS error is coming about because we're making requests from a different and unapproved domain (via our browser), and this can happen whether you're making the request from the client-side, or the server-side (as with node.js and the request and express packages). For a general overview of the nature of server-side vs client-side programming, click below:
See stackexchange -- for more on client vs server sides!
The server-side in general opens up far more options with using the API which go beyond our scope (see the OAuth page). Executing our goal with JavaScript, client-side OAuth as used by Goodreads is nearly impossible, in large part because of the exposed security risks, but I will provide one code example below of a way to get around the CORS violation, and do a similar query as above from the server-side:
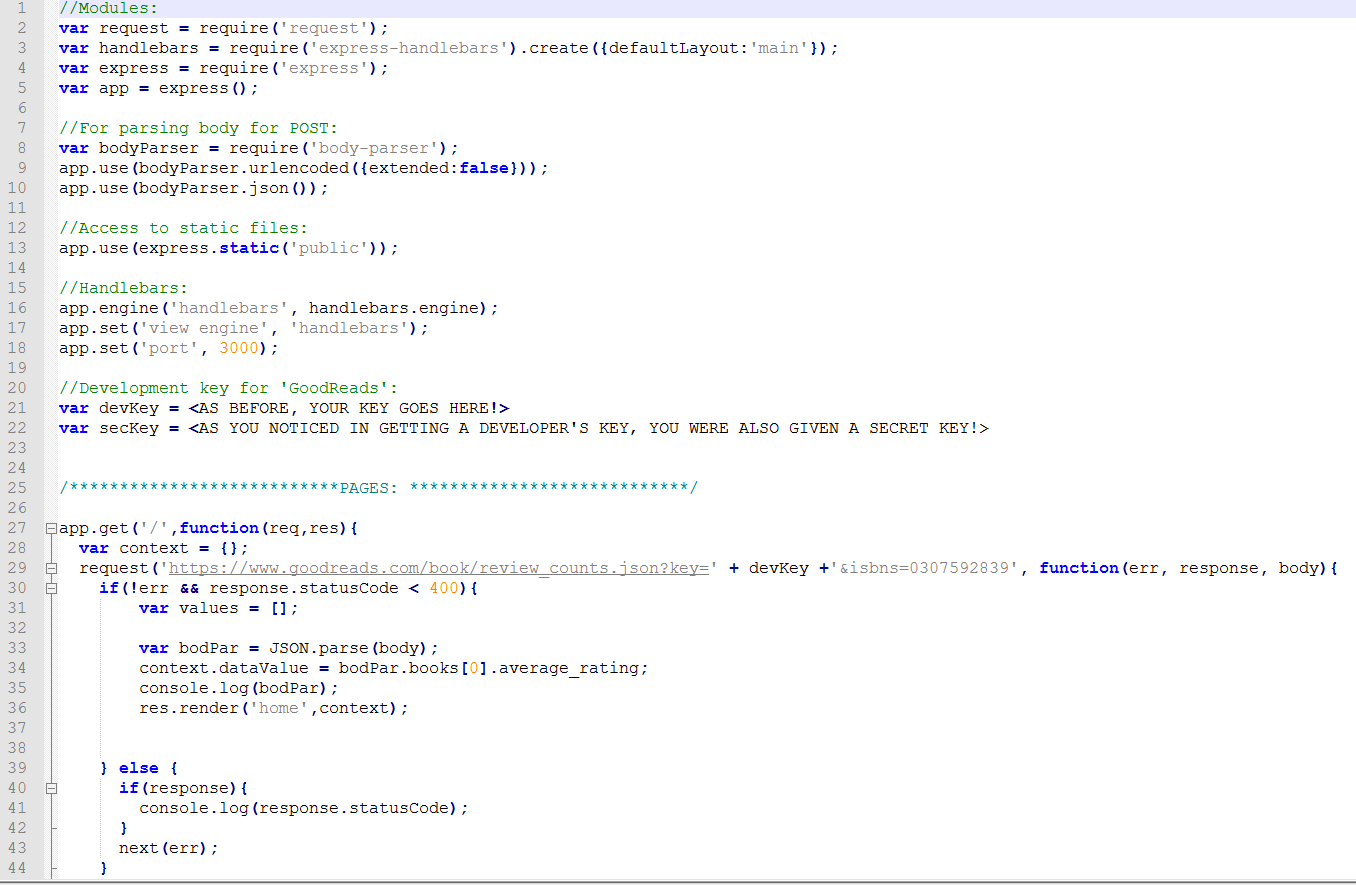
Unlike the client-side script which can run simply by being referred to and properly placed
within a network account's public HTML folder, for example (which does the serving for you),
the script above needs to be served by node.js. At the top, you see the modules required to
successfully run this code ('request' allows getting around CORS violations from this side, vs
the Chrome override you're currently using, handlebars is a templating engine for HTML, and
express.js is a node web application package). These will be denoted in an accompanying 'package'
file (in a JSON format!) so they may be easily grabbed and installed. The body parser allows POST
type methods, and the express.static('public') allows for "static" files, such as the .CSS style
sheets that accompany HTML.
Beneath this we see handlebars being set for templating, and the port for serving. Then our
familiar key. Note here a new key -- one you might have seen at sign-up -- a "secret" developer
key that is for OAuth (see the final page for more on this). This key is used as part of Goodreads's
OAuth process, but we'll not be using it here.
Now to the pages! Without going into excessive detail, you see again our familiar URL for the
GET (here again, our "review_counts") -- and again it is being concatenated with the developer
key like our very first GET. The 'request' function allows the bypassing of CORS violations --
it gives you err, response and body 'containers' which will carry our responses. Again, you see
the JSON is being parsed (here the body of the response, which contains our desired content from
the API), and this is being passed to a context object for display in a specially designated
place on our page (here "home.handlebars" which will template the HTML page).

What follows are more pages, that handle additional queries -- and also error handling (and, as this is server-side, responses or pages for bad URLs and failed transmissions). While the process is very similar, it is more compartmentalized.